
Did you receive an email saying “Page indexing issues detected in submitted URLs for example.com”?
Don’t worry, Let’s find out how to deal with them and how to fix page indexing issues.
What are these page indexing issues?
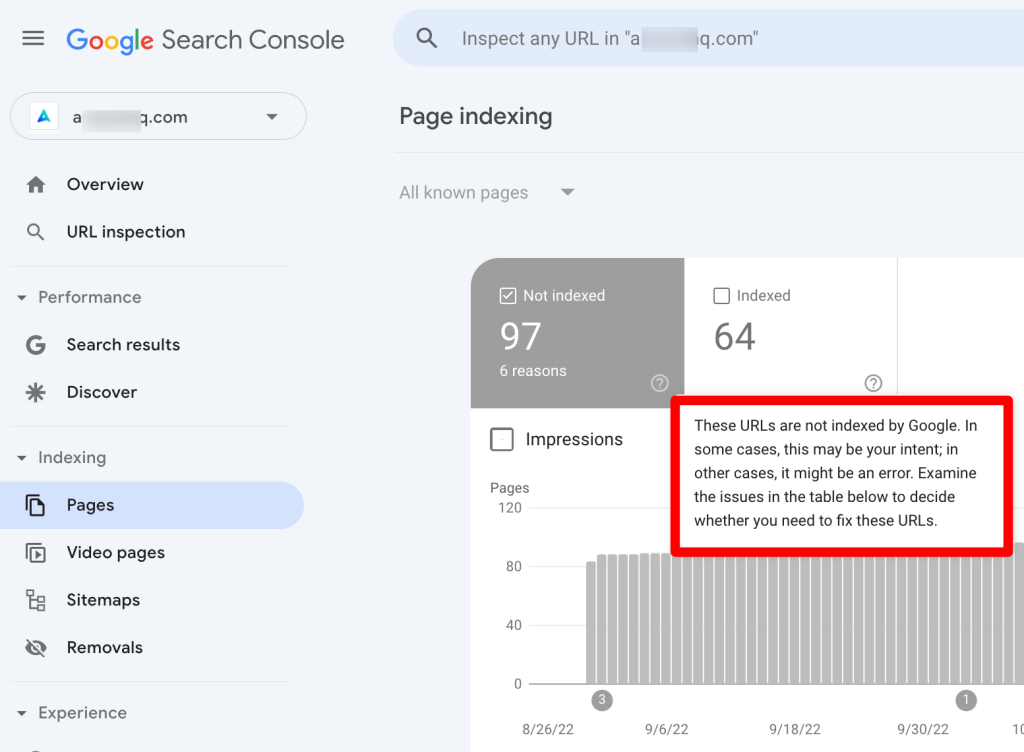
Google Says: “These URLs are not indexed by Google. In some cases, this may be your intent; in other cases, it might be an error. Examine the issues to decide whether you need to fix these URLs or not.“
Don’t Go For Page Indexing Issues Unless you Read this Information:
What to look for:
- Check that all your important URLs are indexed (green).
- If any URLs are not indexed (gray), make sure it’s for a good reason (e.g. robots.txt rule, noindex tag, duplicate URL, or removed page).
- If the total URL count is much smaller than your site’s page count, Google might not be finding all your pages. Reasons for this include having a new site or page, or pages not being findable by Google. Refer to the documentation for specific issues and fixes.
What not to look for:
- Don’t expect every URL to be indexed, as some might be duplicates or not contain meaningful information. Just make sure your key pages are indexed.
- Non-indexed URLs can be fine if there’s a good reason.
- Don’t expect the totals to match your estimated number of URLs, as small discrepancies can occur.
- Even if a page is indexed, it might not show up in every search or in the same ranking.
If you want to learn more on this check the official guide
A quick overview of these page indexing issues;
- Excluded by noindex tag: These are normally blocked from google intentionally. Some good systems (CMS) block many URLs as a good practice so we should filter the URLs carefully. It is very rare that your main pages are found in this head.
- Page with redirect: The URLs reported under this head may or may not have links to fix. The pages with redirect links should be fixed by replacing them with the correct(redirected) link.
- Soft 404: The links reported under soft 404 are normally empty pages or deleted pages.
- Not found (404): The pages or URLs under ‘not found 404’ are the deleted pages that were first indexed by google and later found deleted. These URLs are deleted intentionally most of the time.
- Duplicate, Google chose different canonical than user: Sometimes Google finds some useful pages other than what we choose to pick. This may be picked up temporarily so we can check why google has chosen such URLs to index. In my experience, if the URLs are quite a few then you can ignore them but if the URLs are more than 10% of the total URLs then something needs to be fixed.
- Alternate page with the proper canonical tag: The URLs reported under this section are normally the alternatives to what is indexed already. It is not good to index duplicate content URLs so google normally finds URLs as duplicate pages and doesn’t index them.
- Duplicate without user-selected canonical: Some pages are picked by google as duplicate content pages. But these pages don’t have the preferred URL (canonical) mentioned as well. In this case, we can define the canonical URL in the code to choose our preferred URL for indexing.
- Crawled – currently not indexed: You can check if the reported URLs are important URLs and if these are crawled a week or two ago. If these are important URLs and crawled recently then they will soon be indexed. If the URLs are important but crawled a month ago then you need to increase the quality of that URL by improving the content. You can also increase internal linking to such pages to tell google about the importance of such URLs. However, I find fewer useful pages in this section mostly. Google crawls such pages but doesn’t find them so useful to the index for its users.
- Server error (5xx): These are URLs that were found with server error when the google bot tries to access these URLs.
- Redirect error: These URLs normally redirect to another page which then redirects to another page and causes a redirect error.
When to Fix Page Indexing Issues
We should start checking the reported URLs under each heading to list out URLs that are important to take the recommended action.
We should fix it especially when we have a difference in the number of indexed pages vs the number of available pages for index or the page in the sitemap.
How To Check How Many Available Pages We Have
The quickest way is to go to the sitemap section in the search console and note the number of pages available to index as illustrated below.

There you can see we have 72 pages in the sitemap available for indexing. If you just check the last screenshot of the indexed pages where we have 64 valid pages. It means we just have to find out which 8 pages are not indexed.
We can easily grab this information from discovered currently not indexed or crawled currently not indexed section under the “Not Indexed” area. In rare cases, these missing URLs can be found in the other not-indexing list of issues that needs to be fixed.
Why Google has Reported These Issues
Google may find these issues (non-indexed URLs) within the website and outside of the website. It means we may have filter pages, search pages, the non-canonical pages that might be exhausting the search console indexing log or making it horrific.
The golden rule of thumb is to keep the website clean. The search console is the closest way how google sees our website. This also helps site owners to take any action before it actually causes damage. Each section should be checked to see if there is a real problem or if there is any potential problem that we can fix from the website.
CMS like WordPress, Shopify, and many other have usually apps or plugins which creates functional links that are not needed to be indexed. Filter pages and search pages are one of the main reasons for such issues.
These CMS software (WordPress, Joomla, Big Commerce) have plenty of archive pages (category, tags, date archives) that site owners sometimes don’t aware of. These pages are not useful for site readers. So Google treats them as duplicate content or low-quality pages which is why these pages are often listed in these logs.
You can ignore them if you have indexed pages slightly more than what you have in the sitemaps like you have 100 pages in the sitemap and the search engine is indexing 200 pages. Still, we should why is that.
You should fix it when we have a huge difference in the number of available pages and indexed pages. We have had issues with a hacked (malware-infected) website where the actual site size was around 100 pages and the search console was reporting 50000 pages.
